När tar AI mitt jobb?
Benchmarks som används för att utvärdera AI-system tenderar att gynna frågor som är enkla att ställa till en AI, och enkla att utvärdera eller betygsätta.
Det gör att benchmarks ofta liknar skriftliga prov av det slag man förväntar sig i ett klassrum eller en universitetssal. Notera att även om strukturen på sådana tester kan vara enkel (“ställ en fråga, bedöm om svaret är rätt eller fel”), kan frågorna i sig vara allt annat än enkla. Nedan är två exempelfrågor från benchmarket “Humanity’s last exam”.
Under de senaste åren har många AI-benchmarks blivit mättade — AI-system når nästan perfekta poäng, vilket gör benchmarken oanvändbar för att mäta vidare framsteg. Det väcker en viktig fråga: om AI presterar så bra på benchmarks, varför har det inte haft en större påverkan på arbetsmarknaden?
AI-system kan till exempel klara läkarlegitimationsprov och advokatexamen, men vi ser inte att läkare och advokater ersätts av AI i stor skala i verkligheten. Gapet mellan benchmarkprestationer och verklig påverkan tyder på att dessa tester kanske inte fångar det som faktiskt spelar roll för arbetsprestation.
En förklaring är att de flesta jobb innebär mer än att lösa enskilda uppgifter — just det som benchmarks typiskt mäter. Verkligt arbete kräver att man samordnar flera aktiviteter, anpassar sig till oväntade situationer och integrerar olika kompetenser över tid.
Några nyare benchmarks försöker adressera denna begränsning, och jag vill lyfta två av dem.
METR — Measuring AI Ability to Complete Long Tasks
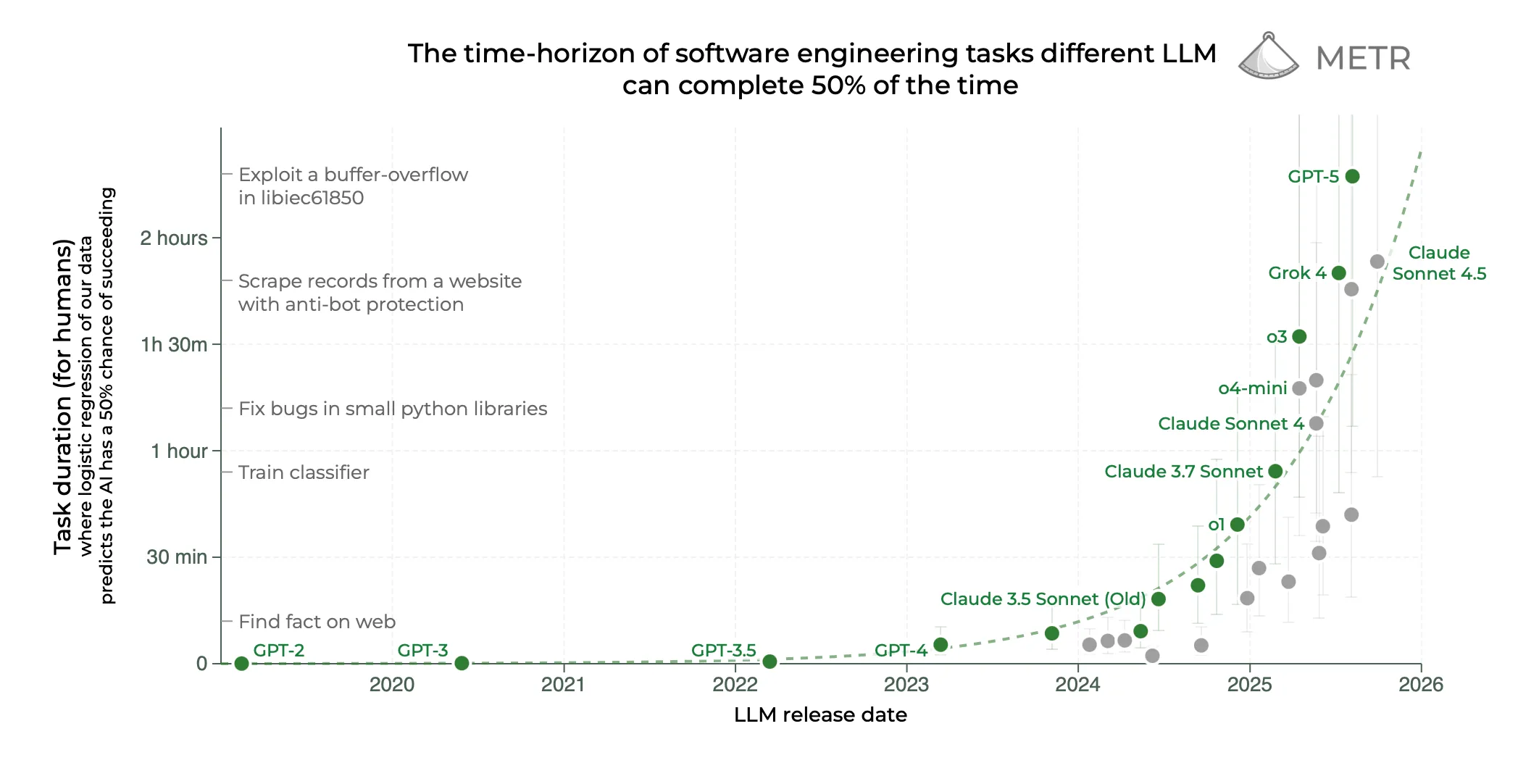
METR (Model Evaluation & Threat Research) är en ideell AI-forskningsgrupp. Deras mest inflytelserika artikel, “Measuring AI Ability to Complete Long Tasks”, föreslår ett nytt sätt att utvärdera AI-modeller: att mäta hur komplexa uppgifter de tillförlitligt kan slutföra.
METR definierar “komplexitet” utifrån hur lång tid det skulle ta en mänsklig expert att slutföra samma uppgift — vad de kallar “tidshorisonten”. En uppgift anses tillförlitligt slutförd om AI:n lyckas 50 % eller 80 % av gångerna. Deras forskning visar att denna tidshorisont har ökat exponentiellt i takt med att nyare och mer kapabla AI-modeller släpps. Den nuvarande bästa modellen (GPT-5) har en tidshorisont på 2 timmar och 17 minuter.
Om trenden fortsätter i samma takt som observerats sedan GPT-2 2019 beräknar METR att AI-modeller kommer att klara heldagsuppgifter (8 timmar) inom ungefär 14 månader. Modeller som kan hantera uppgifter som tar en människa en hel arbetsvecka (40 timmar) kan komma ungefär 20 månader efter det.
OpenAI — GDPval
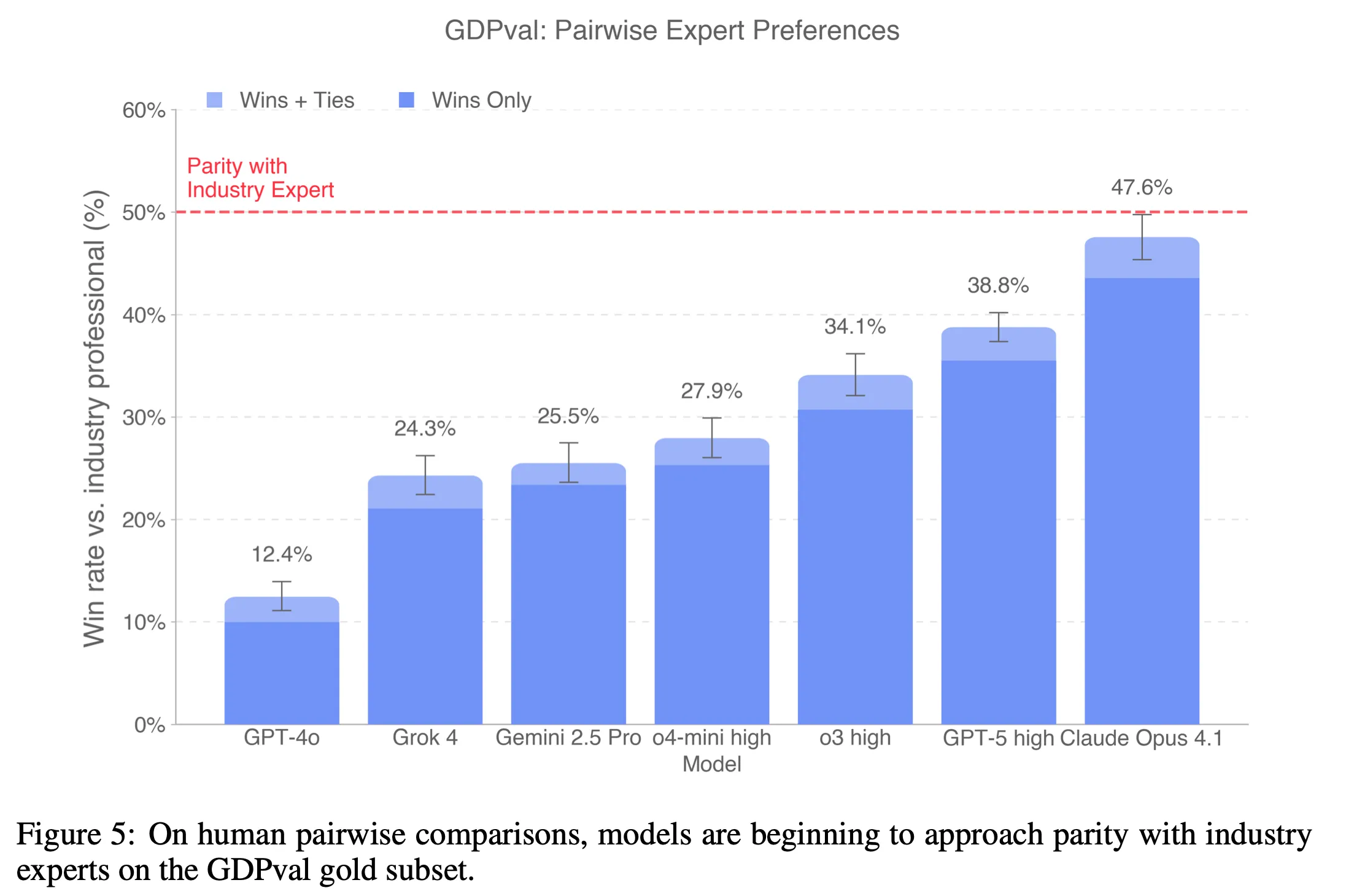
En annan metod för att uppskatta hur stor andel av det ekonomiskt värdefulla arbetet som modeller kan ersätta presenteras i artikeln “GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks”, som bygger på forskning utförd av ett team på OpenAI.
Forskarna bakom studien rekryterade mänskliga experter från 44 yrken inom de 9 största sektorerna i den amerikanska ekonomin. Varje expert definierade en ekonomiskt värdefull uppgift från sitt yrke och levererade sin egen lösning. Det skapade ett dataset med 1 320 uppgifter.
Forskarna lät sedan flera AI-system lösa varje uppgift. En annan grupp mänskliga experter utvärderade alla lösningar — både mänskliga och AI-genererade — och valde den bästa för varje uppgift, utan att veta vilken som var vilken.
Människors lösningar föredrogs generellt, men marginalen var förvånansvärt liten. AI-lösningar föredrogs eller bedömdes som likvärdiga i 47,6 % av uppgifterna. Anmärkningsvärt nog presterade en modell från Anthropic (en av OpenAI:s främsta konkurrenter) bäst totalt sett.
Den genomsnittliga mänskliga tiden för dessa uppgifter var 7 timmar — betydligt längre än METRs observerade tidshorisont på 2 timmar och 17 minuter för den bästa modellen. Skillnaden är att GDPval försåg AI-systemen med detaljerat referensmaterial och kontext, vilket visar värdet av genomtänkt promptteknik. Med rätt kontext kan AI hantera betydligt längre uppgifter än vad METRs benchmark antyder.
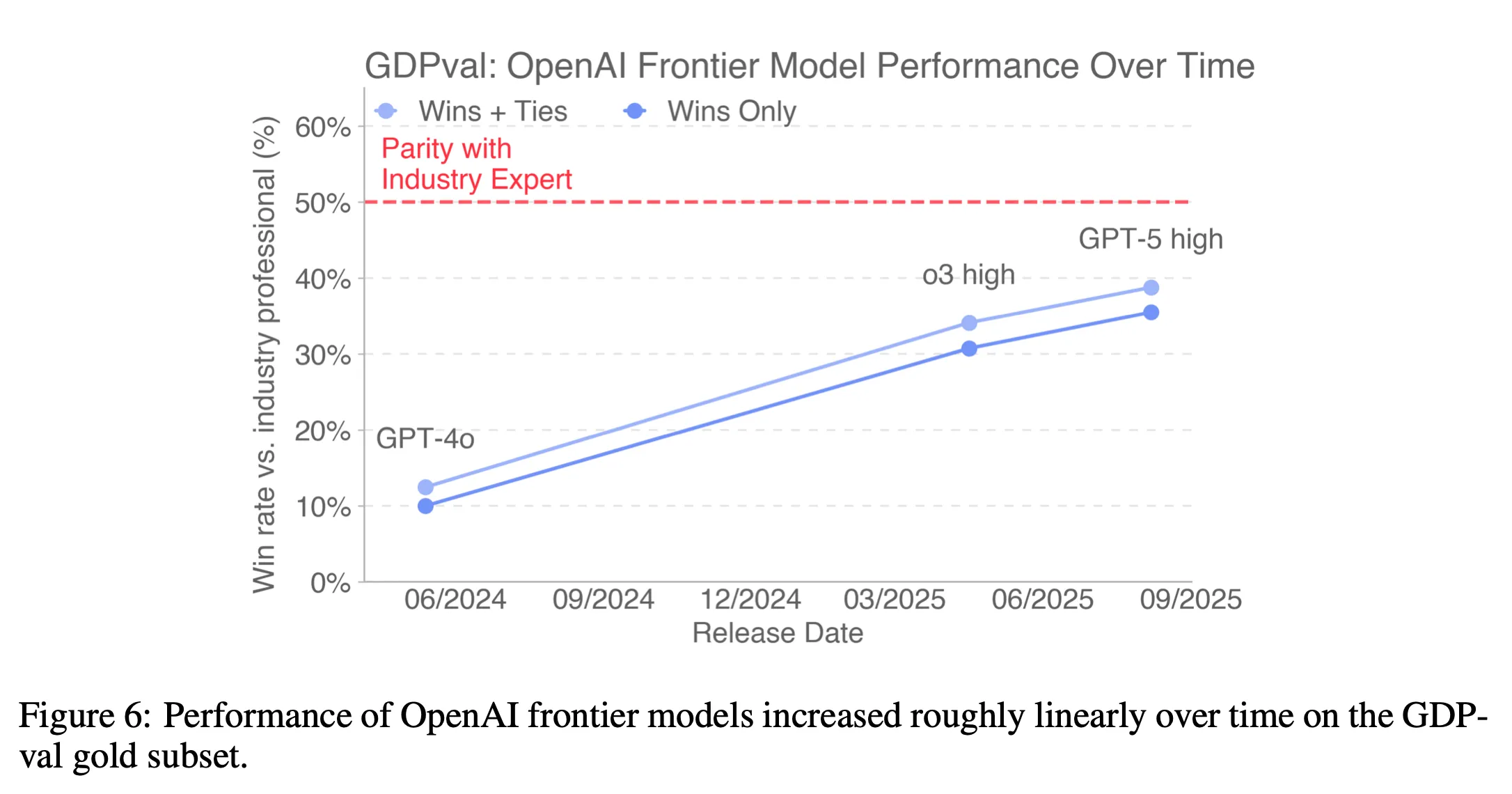
Prestationen hos spjutspetsmodeller från ett specifikt företag (OpenAI) mäts också över tid — och man noterar att flaggskeppsmodellen från förra sommaren (GPT-4o) presterar cirka 20 % sämre jämfört med flaggskeppsmodellen från den här sommaren (o3 high, före lanseringen av GPT-5). En naiv extrapolering skulle innebära att den bästa modellen från OpenAI nästa sommar presterar i nivå med mänskliga experter.
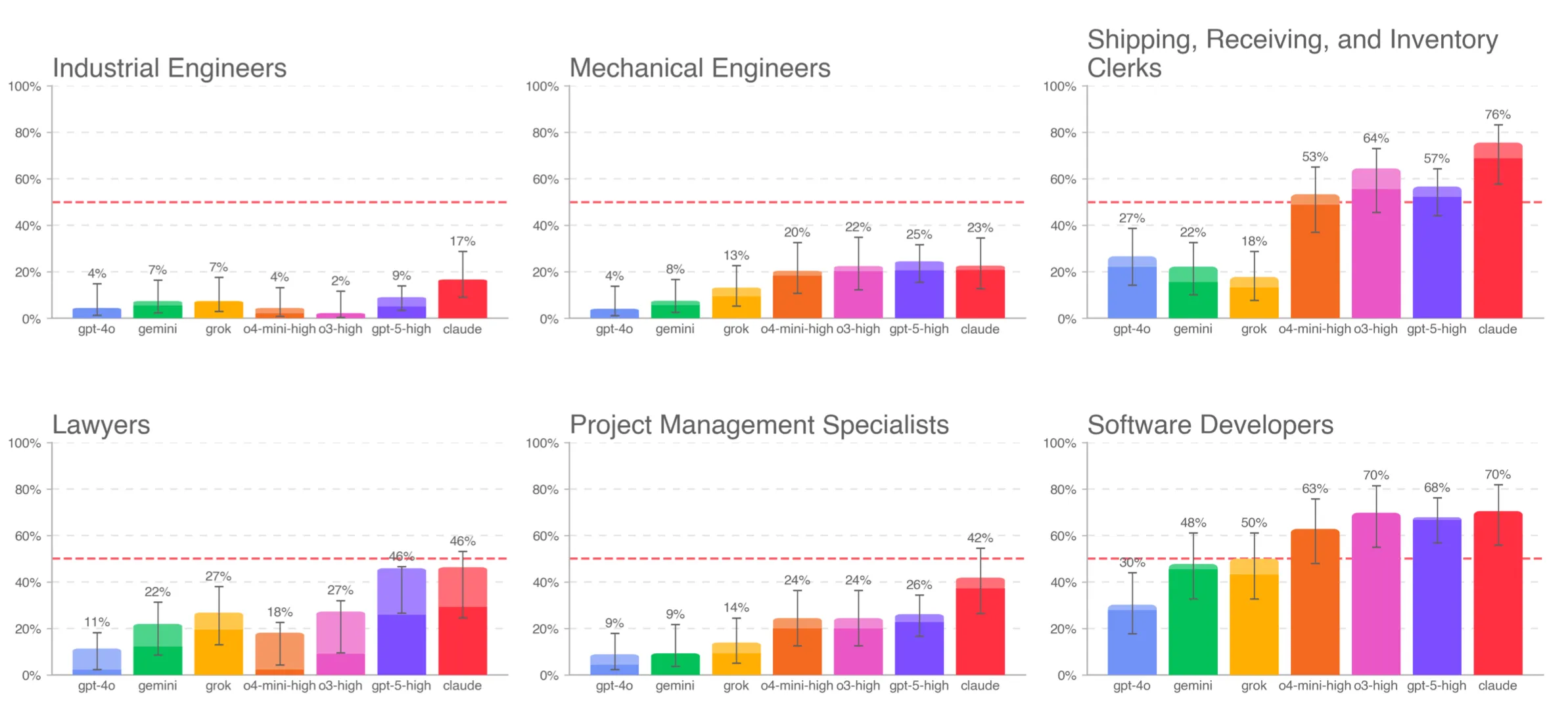
Slutligen observerar forskarna att vissa yrken tenderar att vara betydligt svårare för AI att leverera godtagbara lösningar i jämfört med andra — mänskliga industriingenjörer föredrar de mänskliga lösningarna i 83 % av uppgifterna jämfört med AI, medan mjukvaruutvecklare faktiskt föredrar AI-lösningen i 76 % av uppgifterna.
Så, när tar AI mitt jobb?
Nobelpristagaren 2024 Geoffrey Hinton förutspådde berömt 2016 att vi borde sluta utbilda radiologer, eftersom AI uppenbart skulle vara bättre på deras jobb redan inom det kommande decenniet. 9 år senare är yrket mer efterfrågat än någonsin, trots ökande AI-kapacitet.
Ett jobb är uppenbarligen mer än bara en samling uppgifter att lösa, vilket framgår tydligt av Hintons felaktiga förutsägelse. Andrej Karpathy sa nyligen att han tror att vi är ett decennium från att helt kunna ersätta mjukvaruutvecklare med AI-agenter1.
Med det sagt förbättras AI-modeller kontinuerligt (på ett mycket förutsägbart sätt enligt vissa mätningar, som METRs utvärdering). Och parallellt gör branschen framsteg i att förstå hur man bäst stöttar AI-agenter med stödstrukturer, som välkurerad kontext, för att utföra allt mer komplexa och användbara uppgifter.
De närmaste åren kommer onekligen att bli intressanta.