
Modellen är inte längre flaskhalsen
I april i år lanserade Anthropic ett program de kallar Project Glasswing. Bakgrunden: deras nya AI-modell Mythos visade sig vara så pass kompetent på att hitta säkerhetshål i källkod att Anthropic valde att inte släppa den offentligt direkt. I stället fick ett antal partners — kommersiella företag, infrastrukturprojekt, open source-organisationer — förhandstillgång, med tanken att de skulle hinna lappa sina egna kodbaser innan modellen blev allmänt tillgänglig och attackerare kunde använda den för samma sökning.
Det fick stor uppmärksamhet. Den öppna frågan var hur säker världens digitala infrastruktur kommer att vara den dagen Mythos släpps fritt.
I förra veckan publicerades två genomgångar av vad Mythos hittat i två av världens mest granskade kodbaser, fyra dagar isär. Slutsatserna pekar åt motsatta håll.
Mozilla — organisationen bakom webbläsaren Firefox, med uppemot 200 miljoner användare — skrev den 7 maj att Mythos hjälpt dem identifiera och fixa 271 säkerhetsbuggar bara i Firefox 150. Av dessa klassades 180 som sec-high, det vill säga sårbarheter som kan triggas av att en användare besöker en webbsida. Med patchreleaserna inräknade landade aprils sammanlagda volym på 423 fixade säkerhetsbuggar. Mozilla beskriver det själva som “difficult to overstate how much this dynamic changed for us over a few short months.”
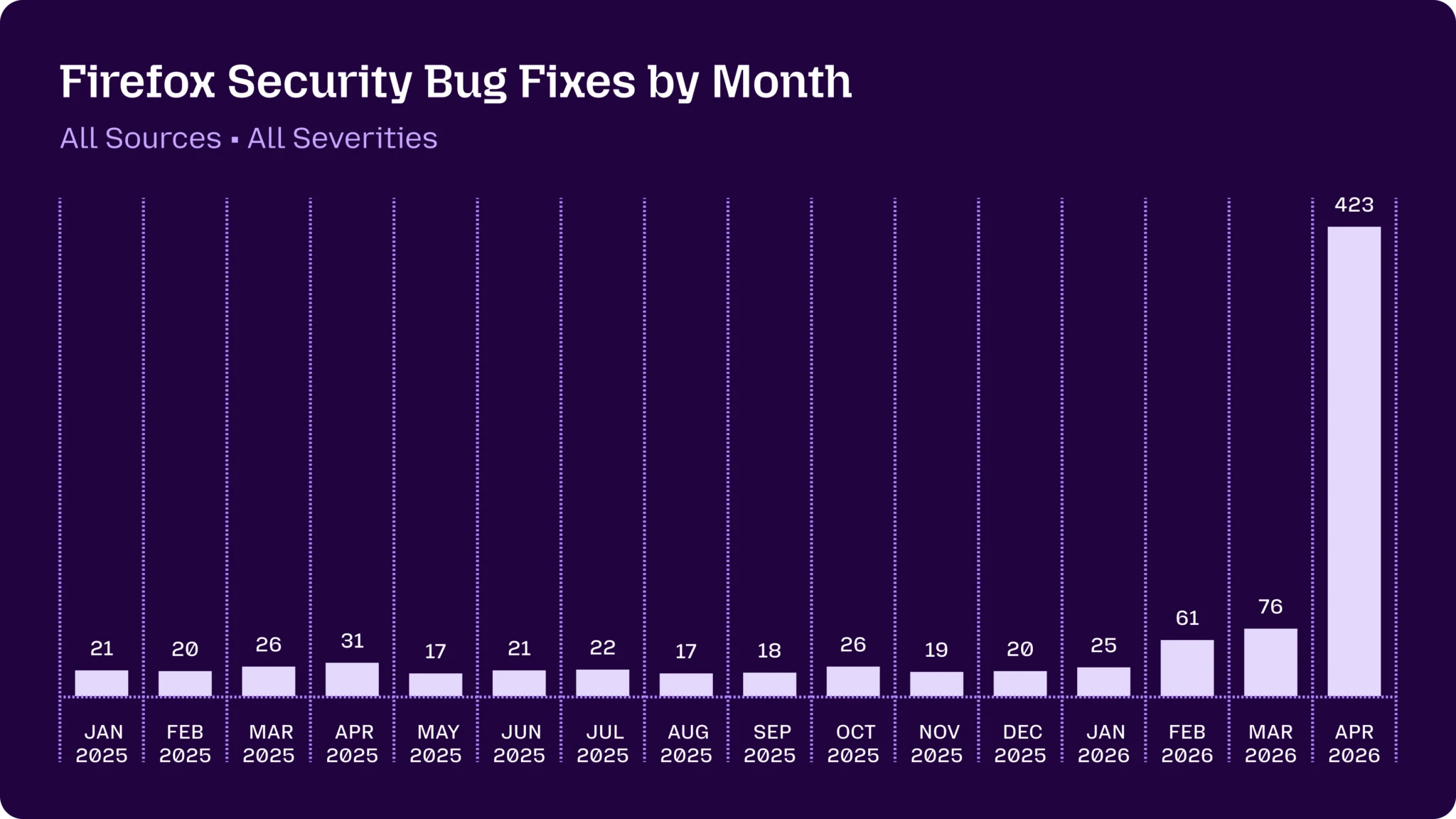 Källa: Mozilla Hacks, “Behind the scenes: hardening Firefox” (7 maj 2026).
Källa: Mozilla Hacks, “Behind the scenes: hardening Firefox” (7 maj 2026).
Daniel Stenberg — huvudutvecklaren bakom curl, ett kommandoradsverktyg och bibliotek för dataöverföring som är installerat i drygt 20 miljarder enheter, från varje mobiltelefon till varje TV och spelkonsol — publicerade sin egen genomgång den 11 maj. Stenberg hade ingen direktåtkomst till modellen själv — efter veckors väntan på den utlovade tillgången lät han istället någon annan med Glasswing-tillgång köra scanningen och skicka tillbaka rapporten. Mythos hittade fem “bekräftade säkerhetsproblem” i curl (enligt Mythos själv, då). Stenbergs säkerhetsteam tittade igenom dem och kom fram till att tre var falska positiv, en var “bara en bugg”, och en blir en CVE med severity low som släpps med curl 8.21.0 i juni. Stenbergs slutsats: primarily marketing.
Samma modell. 270 gånger så stor skillnad i utfall. Frågan är varför.
Harness, inte modellen
Skillnaden ligger inte i modellen. Den ligger i vad som omger den.
Stenberg fick en scan. En person körde Mythos mot curl-källkoden och skickade tillbaka en rapport. Metoden beskrivs i rapporten själv: hand-driven analysis using LLM subagents for parallel file reads. Statisk analys. En vända. En PDF.
Mozilla byggde en harness — en agentstruktur — ovanpå sin existerande fuzzing-infrastruktur. Modellen får verktyg, kan skapa reproducerbara testfall, dynamiskt testa hypoteser, iterera, och filtrera bort falska positiv själv. Allt körs parallellt över många tillfälliga maskiner, var och en inriktad på sin egen del av koden. Sedan en hel pipeline runt det: deduplicering mot kända problem, triagering, fix-shipping, releasehantering. Över 100 personer involverade på mottagarsidan.
Det är två olika produkter, inte två varianter av samma. Stenbergs invändning — att Mythos är primarily marketing — är lokalt rimlig för hans access-mönster och hans kodbas. Men han testade en motor utan att bygga ett chassi. Mozilla byggde chassit.
Värt att tillägga: curl och Firefox är dessutom väldigt olika kodbaser. curl är 176 000 rader C-kod — ett fokuserat nätverksbibliotek som gör en sak (hämta data via internet) och som av många ses som guldstandard för säkerhetsarbete i öppen källkod. Mythos egen rapport beskrev curl som “one of the most fuzzed and audited C codebases in existence”. Firefox är drygt 21 miljoner rader kod i flera språk (C++, Rust, JavaScript, Python) — en hel webbläsare med JavaScript-motor, sandlåda, IPC och renderingsmotor. En del av skillnaden i utfall förklaras alltså av att Firefox har mer kod, och fler typer av kod, att hitta buggar i. Men inte hela. Den dominerande faktorn är hur de två rapporterna kom till.
Codex /goal och ARC-AGI-3
ARC-AGI är ett benchmark för abstrakt resonemang — uppgifter som är enkla för människor men har visat sig svåra för AI. Skapat 2019 av François Chollet (en av forskarna bakom Keras) för att fånga skillnaden mellan minneskrävande mönsterigenkänning och äkta generaliseringsförmåga. Varje uppgift består av ett par exempel på en transformationsregel; deltagaren ska klura ut regeln och tillämpa den på en ny instans. Benchmarken har sedan dess uppdaterats i två iterationer som båda gjort uppgifterna hårdare.
Den senaste, ARC-AGI-3, släpptes den 25 mars 2026 och är designad specifikt för att exponera vad frontier-modellerna inte kan: utforska okända miljöer, bygga världsmodeller, identifiera mål utan att få instruktioner om dem, och planera och justera under exekvering. Resultaten vid lansering:
- Människor: alla miljöer kan lösas
- Gemini 3.1 Pro Preview: 0,37 %
- GPT 5.4: 0,26 %
- Opus 4.6: 0,25 %
- Grok-4.20: 0 %
Sex veckor senare, den 30 april, släppte OpenAI ett nytt experimentellt slash-kommando i Codex: /goal. Inte en ny modell. En harness. En ihållande loop som planerar, agerar, testar, granskar och itererar — tills målet är uppfyllt eller budgeten slut. OpenAI kallar det internt Ralph Loop, efter en bash-loop-teknik som Geoffrey Huntley namngav sommaren 2025 och som spritt sig snabbt i den agentiska kodningssfären sedan dess. /goal byggs in i både Codex CLI och Codex-appen.
Inom dagar körde någon Codex med /goal mot ARC-AGI-3:s public set.
Resultat: 61 % på public set.
Värt att vara försiktig med vad det betyder. Det är på public set, inte på de privata eller semi-privata setten som räknas för officiell leaderboard. Scorecarden är inte verifierad av ARC Prize, och de varnar själva för att inte tolka community-resultat som AGI-progress. Men magnituden står där: från under 1 % till 61 % på ett par veckor. Inte för att modellen förändrades. För att harnesset gjorde det.
Notera också vad ARC-AGI-3 var byggt för att testa: just goal-setting. Och vad som knäckte det: en harness som heter /goal. Det är ett benchmark-resultat som dubbar som en självillustrerande poäng.
Vad det betyder
Hela 2023 och 2024 handlade om vilken modell. Vilken är bäst på SWE-bench, vilken kostar minst, vilken har längst kontext. Den frågan är inte oviktig, men det är inte längre den avgörande frågan.
Två datapunkter pekar samma håll:
- Stenberg vs. Mozilla: samma modell, 270× skillnad i utfall — harness.
- Codex /goal + ARC-AGI-3: ett benchmark designat för att avslöja modellbrister, knäckt på två veckor av en goal-loop — harness.
Det är inte längre anekdotiskt. Det är ett mönster med uppbackning från ett externt benchmark vars hela syfte är att vara svårt att fuska sig genom.
För dig som beställare av AI-strategi: om frågeställningen fortfarande är vilken modell ska vi använda så optimerar du fel variabel. Den avgörande frågan de närmaste tolv månaderna är vilken loop, vilken budget, vilken audit. Välj harness-mönstret först. Modellen blir utbytbar.
För dig som bygger AI-system själv: agentstrukturer kring befintliga modeller ger märkbart bättre output än rå inferens. Tröskeln för att börja är låg. Codex /goal eller en hand-rullad Ralph-loop i bash är båda rimliga startpunkter. Det är hyllvara nu.
För säkerhetsteamet: er fråga är inte längre om ni har skannat koden. Det är hur. Mozillas pipeline är beskriven offentligt nog att studera. Stenberg är själv tydlig på den punkten: “Not using AI code analyzers in your project means that you leave adversaries and attackers time and opportunity to find and exploit the flaws you don’t find.”
Det som inte är klart än
Två saker är värda att hålla i huvudet samtidigt.
Det första är att harness-resultaten inte är gratis. Mozillas pipeline står på över hundra personers arbete, en mogen fuzzing-infrastruktur, och en organisation som kan ta emot 423 buggrapporter på en månad. Stenberg har en maintainer. Det är inte samma utgångsläge, och rådet att “bygga en harness” ser olika ut beroende på var man står. För mindre projekt är den realistiska första versionen troligen ett färdigt verktyg som Codex /goal snarare än något hand-byggt.
Det andra är att 61 % på ARC-AGI-3 är på public set och inte officiellt verifierat. Det är inte AGI. Men trenden — same model, vastly different output beroende på harness — är robust. Det räcker för att flytta vad man bör fokusera på.
Två veckor från Codex /goal shippade till 61 % på ARC-AGI-3 public set. Det benchmark som skulle vara svårt att slå i flera år visade sig svårt i en del på ett par veckor. Det säger inget om AGI. Det säger en del om vad man bör investera tid i de närmaste tolv månaderna.