
The Model Is No Longer the Bottleneck
In April this year, Anthropic launched a program they call Project Glasswing. The background: their new AI model Mythos turned out to be capable enough at finding security vulnerabilities in source code that Anthropic decided not to release it publicly straight away. Instead, a number of partners — commercial companies, infrastructure projects, open source organizations — received early access, with the idea that they would have time to patch their own codebases before the model became publicly available and attackers could use it for the same kind of search.
It attracted significant attention. The open question was how secure the world’s digital infrastructure would be on the day Mythos is released into the wild.
Last week, two reviews were published of what Mythos found in two of the world’s most scrutinized codebases, four days apart. The conclusions point in opposite directions.
Mozilla — the organization behind the Firefox browser, with roughly 200 million users — wrote on May 7 that Mythos had helped them identify and fix 271 security bugs in Firefox 150 alone. Of those, 180 were classified as sec-high — vulnerabilities that can be triggered simply by a user visiting a webpage. Including patch releases, April’s total came to 423 fixed security bugs. Mozilla’s own words: “difficult to overstate how much this dynamic changed for us over a few short months.”
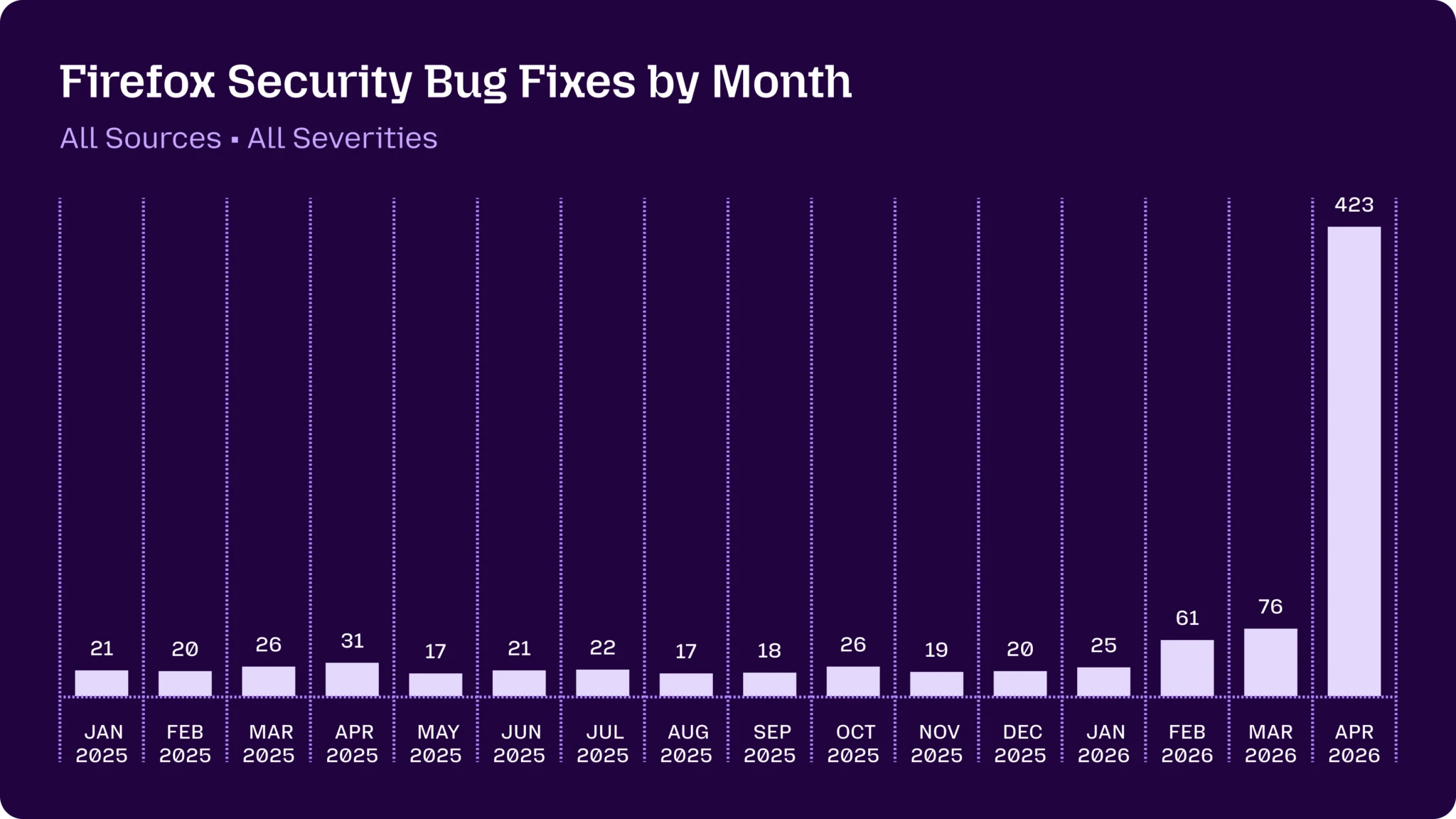 Source: Mozilla Hacks, “Behind the scenes: hardening Firefox” (May 7, 2026).
Source: Mozilla Hacks, “Behind the scenes: hardening Firefox” (May 7, 2026).
Daniel Stenberg — the lead developer behind curl, a command-line tool and library for data transfer installed on over 20 billion devices, from every mobile phone to every TV and game console — published his own review on May 11. Stenberg had no direct access to the model himself — after weeks of waiting for the promised access, he had someone else with Glasswing access run the scan and send back the report. Mythos found five “confirmed security issues” in curl (according to Mythos itself, at the time). Stenberg’s security team went through them and concluded that three were false positives, one was “just a bug,” and one will become a CVE with severity low, shipping with curl 8.21.0 in June. Stenberg’s verdict: primarily marketing.
Same model. A 270-fold difference in outcomes. The question is why.
Harness, not the model
The difference is not in the model. It’s in what surrounds it.
Stenberg got a scan. Someone ran Mythos against the curl source code and sent back a report. The method is described in the report itself: hand-driven analysis using LLM subagents for parallel file reads. Static analysis. One pass. One PDF.
Mozilla built a harness — an agent scaffolding — on top of their existing fuzzing infrastructure. The model gets tools, can create reproducible test cases, dynamically test hypotheses, iterate, and filter out false positives on its own. Everything runs in parallel across many ephemeral machines, each focused on its own slice of the code. Then a full pipeline around that: deduplication against known issues, triage, fix-shipping, release management. Over 100 people involved on the receiving end.
These are two different products, not two variants of the same thing. Stenberg’s objection — that Mythos is primarily marketing — is locally reasonable for his access pattern and his codebase. But he tested an engine without building a chassis. Mozilla built the chassis.
Worth adding: curl and Firefox are also very different codebases. curl is 176,000 lines of C code — a focused network library that does one thing (fetch data over the internet) and is widely considered the gold standard for security work in open source. Mythos’s own report described curl as “one of the most fuzzed and audited C codebases in existence.” Firefox is over 21 million lines of code across multiple languages (C++, Rust, JavaScript, Python) — an entire browser with a JavaScript engine, sandbox, IPC, and rendering engine. Part of the difference in outcomes is explained by the fact that Firefox has more code, and more types of code, to find bugs in. But not all of it. The dominant factor is how the two reports came to exist.
Codex /goal and ARC-AGI-3
ARC-AGI is a benchmark for abstract reasoning — tasks that are easy for humans but have proven difficult for AI. Created in 2019 by François Chollet (one of the researchers behind Keras) to capture the difference between memory-intensive pattern recognition and genuine generalization ability. Each task consists of a pair of examples of a transformation rule; the participant must figure out the rule and apply it to a new instance. The benchmark has since been updated in two iterations, both of which made the tasks harder.
The latest, ARC-AGI-3, was released on March 25, 2026 and is designed specifically to expose what frontier models cannot do: explore unfamiliar environments, build world models, identify goals without being given instructions about them, and plan and adjust during execution. Results at launch:
- Humans: all environments solvable
- Gemini 3.1 Pro Preview: 0.37%
- GPT 5.4: 0.26%
- Opus 4.6: 0.25%
- Grok-4.20: 0%
Six weeks later, on April 30, OpenAI shipped a new experimental slash command in Codex: /goal. Not a new model. A harness. A persistent loop that plans, acts, tests, reviews, and iterates — until the goal is met or the budget runs out. OpenAI calls it internally Ralph Loop, after a bash loop technique named by Geoffrey Huntley in the summer of 2025 that has spread rapidly through the agentic coding world since. /goal is being built into both the Codex CLI and the Codex app.
Within days, someone ran Codex with /goal against ARC-AGI-3’s public set.
Result: 61% on the public set.
Worth being careful about what that means. It’s on the public set, not the private or semi-private sets that count for the official leaderboard. The scorecard hasn’t been verified by ARC Prize, and they themselves warn against interpreting community results as AGI progress. But the magnitude stands: from under 1% to 61% in a couple of weeks. Not because the model changed. Because the harness did.
Also note what ARC-AGI-3 was built to test: precisely goal-setting. And what cracked it: a harness called /goal. That’s a benchmark result that doubles as a self-illustrating point.
What it means
All of 2023 and 2024 was about which model. Which one scores best on SWE-bench, which costs least, which has the longest context. That question isn’t unimportant, but it’s no longer the decisive one.
Two data points point the same direction:
- Stenberg vs. Mozilla: same model, 270× difference in outcomes — harness.
- Codex /goal + ARC-AGI-3: a benchmark designed to expose model weaknesses, cracked in two weeks by a goal loop — harness.
This is no longer anecdotal. It’s a pattern backed by an external benchmark whose entire purpose is to be hard to game.
If you’re commissioning AI strategy: if the question is still which model should we use, you’re optimizing the wrong variable. The decisive question for the next twelve months is which loop, which budget, which audit. Choose the harness pattern first. The model becomes interchangeable.
If you’re building AI systems yourself: agent scaffolding around existing models produces markedly better output than raw inference. The barrier to entry is low. Codex /goal or a hand-rolled Ralph loop in bash are both reasonable starting points. It’s available off the shelf now.
For the security team: your question is no longer whether you’ve scanned the code. It’s how. Mozilla’s pipeline is described publicly enough to study. Stenberg himself is clear on this point: “Not using AI code analyzers in your project means that you leave adversaries and attackers time and opportunity to find and exploit the flaws you don’t find.”
What’s not settled yet
Two things are worth holding in mind at the same time.
The first is that harness results don’t come free. Mozilla’s pipeline runs on over a hundred people’s work, a mature fuzzing infrastructure, and an organization capable of absorbing 423 bug reports in a month. Stenberg has one maintainer. That’s not the same starting point, and the advice to “build a harness” looks different depending on where you’re standing. For smaller projects, the realistic first version is probably a ready-made tool like Codex /goal rather than something hand-built.
The second is that 61% on ARC-AGI-3 is on the public set and hasn’t been officially verified. It’s not AGI. But the trend — same model, vastly different output depending on harness — is robust. That’s enough to shift what you should be focusing on.
Two weeks from Codex /goal shipping to 61% on the ARC-AGI-3 public set. The benchmark that was supposed to be hard to beat for years turned out to be hard in one part for a couple of weeks. That says nothing about AGI. It says quite a bit about where to invest time over the next twelve months.